Tech-25/02/2025
The Lakehouse Era: How Open Storage and Stateless Compute Are Reshaping Data Infrastructure
In the last two decades, data infrastructure has undergone dramatic shifts. We’ve moved from tightly-coupled data systems like Hadoop to cloud data warehouses that separate storage and compute, and now toward the lakehouse – an architecture blending the strengths of data lakes and data warehouses. This article explores that evolution, highlighting why each shift occurred and how the modern lakehouse paradigm addresses previous limitations.

The Early Era of Big Data: Hadoop and Data Locality
In the mid-2000s, as data volumes exploded, Apache Hadoop emerged as the dominant large data processing framework. Hadoop’s design philosophy was to bring compute to the data. It accomplished this via two core components:
- The Hadoop Distributed File System (HDFS) for storage
- The MapReduce processing framework for compute
HDFS would split large datasets into blocks and distribute them across many commodity servers (nodes). MapReduce jobs were then sent to run on the same nodes where the data blocks resided, a concept known as data locality. By processing data on local disks, Hadoop minimized network transfers and achieved high aggregate throughput. This approach was a response to hardware realities of that era – network bandwidth in 2006 was a major bottleneck compared to disk throughput. Running tasks where the data lived was simply more efficient than shipping big data over slow networks.
Advantages of the Hadoop Approach
At the time, this architecture had clear benefits. It harnessed cheap commodity hardware in a cluster to store massive datasets reliably (with replication) and process them in parallel. Data locality delivered faster processing by reducing data movement, making it possible to scan many terabytes efficiently with MapReduce. In essence, Hadoop provided a scalable, fault-tolerant way to do big batch analytics with a shared-nothing design – each node handled its portion of data independently, avoiding centralized bottlenecks.
Limitations of Data Locality
However, Hadoop’s tightly-integrated storage-and-compute model also revealed limitations as technology and needs evolved. One issue was inflexible scaling: storage and compute were bundled on the same machines, so scaling one meant scaling both. If you needed more storage for growing data, you had to add more compute nodes (even if CPU was under-utilized), and vice versa. Over time, many enterprises found that data growth far outpaced their growth in compute needs. This often led to excess capacity and wasted cost – clusters were over-provisioned with CPU/RAM that went idle, simply because more disks were needed.
Another shifting factor was cost of storage. In Hadoop’s early days, storing lots of data on-premise was expensive, so HDFS’s use of commodity drives (with 3x replication) was cost-effective. But cloud object storage services (like Amazon S3) soon offered vastly cheaper per-gigabyte costs due to economies of scale. By 2017, estimates showed that Amazon S3 could be five times cheaper than HDFS on an equivalent dataset. In fact, when accounting for operational overhead (the “human cost” of maintaining Hadoop clusters), cloud storage was roughly 10x cheaper than DIY HDFS. This economic shift began to undercut one of Hadoop’s core assumptions – that you should keep data within your compute cluster. As storage shifted from a scarce resource to an abundant commodity (in the cloud), the rationale for coupling compute tightly with storage weakened.
Hadoop and data locality pioneered big data analytics by solving the problems of their time (slow networks, costly storage, and unreliable hardware) with an ingenious architecture. But as hardware improved and cloud services emerged, the cracks in that tightly-coupled design started to show. Organizations needed more flexibility than Hadoop’s all-in-one approach could provide, paving the way for a new paradigm.
The Shift to the Separation of Storage and Compute
Entering the 2010s, two trends prompted a fundamental change in data architecture: cloud infrastructure and cheap, scalable storage. Cloud providers offered virtually unlimited storage (e.g. S3, Google Cloud Storage, Azure Blob Storage) at low cost, independent of compute. This made it feasible – and attractive – to decouple storage from compute in analytics platforms. Rather than storing data on the same nodes that do the computing (as Hadoop did), cloud data warehouses began storing data in a central service (a cloud storage layer) and spinning up compute resources on-demand to query that data.
The poster children of this approach are Snowflake and Google BigQuery. Snowflake (launched mid-2010s) was designed from the ground up as a cloud data warehouse with a separate storage layer (on S3) and compute layer. BigQuery, similarly, built on Google’s distributed filesystem (Colossus) for storage and decoupled query processing nodes that can elastically scale. This separation of compute and storage became the new state of the art, allowing these services to leverage the cloud’s “infinite” resources. Under this model, data is persisted in inexpensive storage (often columnar files in object storage), and compute clusters can be spun up, resized, or shut down independently, based on workload demand.
Why was this so transformative?
First, it unlocked elasticity. In a decoupled architecture, you can dynamically dial compute up or down without moving data. Need more power for a heavy query or a spike in users? Just add more compute nodes or clusters – the storage layer remains the same. When the work is done, you can release those resources and stop paying for them. Snowflake, for example, lets different teams or jobs use separate compute clusters (ensuring workload isolation) but all access the same single copy of the data. BigQuery, being serverless, automatically allocates more resources to queries as needed. This flexibility meant far better utilization and cost-efficiency: companies no longer had to keep a huge Hadoop cluster running 24/7 “just in case” peak jobs come; they could scale out for an hour and scale back in.
Second, decoupling took advantage of pay-as-you-go economics. Cloud storage has a pay-per-use model and essentially unlimited capacity. There’s no complex capacity planning or large upfront hardware purchases – you store as much data as you need, and you pay only for what you use. If you suddenly ingest a huge dataset, you simply see a higher storage bill, but you don’t need to procure new servers or re-architect anything. This elasticity extends to compute costs as well: spinning up compute only when needed avoids the idle hardware costs of the Hadoop era. As the Databricks team put it, “One of the nicest benefits of S3, or cloud storage in general, is its elasticity and pay-as-you-go pricing model… if you need to put more data in, just dump it there… the cloud provider automatically provisions resources on demand. Simply put, S3 is elastic, HDFS is not.”
There were trade-offs to this new model, but technology advancements largely mitigated them. In a decoupled system, compute nodes no longer enjoy local disk access; every data read goes over the network from the storage service. Initially, one might fear a return to the dreaded network bottlenecks of pre-Hadoop days. Indeed, on a per-node basis, local HDFS reads can be faster – one benchmark showed a single Hadoop node could read at ~3 GB/s from its disks, whereas a cloud object store might deliver ~600 MB/s to a node.
But two factors made this a non-issue: (1) networks got much faster (within data centers, 10 Gbps and higher is now common, versus 1 Gbps in 2006), and (2) you can compensate by scaling out compute. If each node gets slightly lower throughput from remote storage, you can just run more nodes in parallel for large scans, since compute is no longer tied to storage. Because storage is cheap and the overall cost per performance is better, users found it was still advantageous. In fact, despite lower single-node throughput, the cost-performance often improved: S3’s low price more than offsets its lower speed, making it almost 2x better than HDFS on performance per dollar. In short, any loss of data locality was countered by cloud scale and economics.
This shift enabled new usage patterns as well. Companies could share a single storage “lake” across multiple query clusters and services. For example, raw data could be stored once in S3, and Snowflake, AWS Athena, or Spark could all run queries on it (with proper access). We’ll shortly discuss the challenges this introduced – but the immediate benefit was tremendous agility. Data teams could choose the best compute tool for each job without worrying about where the data lived, since all compute layers connected to the same durable storage. The separation of storage and compute is now a baseline for almost all modern data platforms. It underpins not just Snowflake and BigQuery, but also Amazon Redshift Spectrum, Azure Synapse, Databricks’ Delta Lake, and many others.
At the end of the day, decoupling storage and compute was a response to cloud capabilities: it made analytics more scalable, flexible, and cost-efficient. It solved Hadoop’s scaling pain points (no more over-provisioning just for storage) and capitalized on the steep drop in storage costs (store everything, worry less about space). By the late 2010s, this approach had become the norm for new data infrastructure. However, it wasn’t without new difficulties – chief among them was the proliferation of data silos across different compute tools, which we address next.
The Challenge of Data Fragmentation
The separation of storage and compute unlocked flexibility – theoretically, multiple compute engines could access the same data in the central storage. In practice, however, many organizations found themselves dealing with data fragmentation in this new landscape. The issue was that while storage became a common layer, the analytical engines on top were diverse (each with its own formats, optimizations, and ecosystems). Without careful design, teams ended up creating multiple copies of data for different purposes, undermining the single-source-of-truth ideal.
A common scenario circa 2015-2020 was to maintain both a data warehouse and a data lake. For instance, an enterprise might load critical data into Snowflake or BigQuery for BI dashboards and SQL analytics, but also keep the raw or detailed data in an S3 data lake accessible to Spark or Python for data science work. Since traditional warehouses are often closed systems, using external frameworks (like Apache Spark for ML or custom data applications) meant exporting or duplicating data out of the warehouse into files on the data lake. Similarly, if some data originated in a data lake (say in Parquet files), analysts might ingest a subset of it into a warehouse for easier reporting. The result was data in many places: siloed copies in BigQuery, in Amazon S3, maybe in a NoSQL store, etc., each serving different tools or teams.
This fragmentation led to several problems:
- Duplication and Cost: Storing multiple copies wastes storage and increases costs. Maintaining pipelines to keep datasets in sync (e.g. ETL jobs from the lake to the warehouse) adds engineering overhead. As an AWS blog observed, “data is spread across data lakes, data warehouses, and different applications… This fragmentation leads to duplicate data copies and complex data pipelines, which in turn increases costs for the organization.” Every extra copy of data not only costs money to store, but also requires time/effort to update whenever the source data changes.
- Inconsistency: The moment you have two copies of the same data, you risk them falling out of sync. If one pipeline is delayed or fails, analysts might see outdated information in one system compared to another. It became challenging to answer questions like “which is the source of truth for metric X?” because data might be slightly different across Snowflake, S3, and other systems. Users had to reason about which copy of the data their tool was hitting. In the separated storage era, it was common to hear frustrations like “the numbers in our BI dashboard don’t match what our data science notebook shows,” often caused by such fragmentation.
- Siloed Compute Choices: Another downside was lack of cross-engine interoperability. Each system had its own interface – SQL in the warehouse, data frames in Spark, etc. If a user wanted to use a different engine on a dataset, they frequently had to move or transform the data first. For example, if data was loaded into BigQuery, using Apache Spark on it meant exporting that data to Cloud Storage and then running Spark – a multi-step process. This friction limited agility and encouraged even more copies (one copy tuned for BigQuery, another for Spark).
- Complex Data Lineage: With pieces of data flowing to many places, tracking data lineage and governance became harder. Answering “where did this data come from and who changed it?” might require stitching together logs from multiple systems. It was the opposite of the ideal single controlled repository.
In essence, decoupling storage and compute solved one problem and revealed another: how do you maintain a single source of truth when you have a multitude of engines and platforms? Without a unifying layer, users often fell back to siloed workflows, each gravitating to the platform that best met their needs, and then gluing things together manually. This highlighted the need for an architectural evolution to re-unify data infrastructure at the storage level without sacrificing the compute flexibility we’d gained.
Realizations & Mitigating Actions from Cloud Providers
Some of the big cloud vendors themselves started to address this. Google, for instance, introduced BigLake (as an extension of BigQuery) to let BigQuery query data in Google Cloud Storage and unify metadata across warehouse and lake. Amazon introduced services like Redshift Spectrum (to query S3 data from Redshift) and later AWS Lake Formation (for centralized governance across services). These were steps toward blending the lines between warehouses and lakes. The underlying message in the market was clear: users wanted seamless access to data across systems. The status quo of copying data between specialized systems was unsustainable.
This realization set the stage for the lakehouse concept. But a crucial enabler was still needed: a way to store data in an open format such that many different engines could use it concurrently and consistently. This is where the rise of open table formats like Apache Iceberg and Apache Hudi played a pivotal role in the emergence of the lakehouse paradigm.
The Rise of Open Table Formats: Iceberg, Hudi, and friends
To break down data silos and enable a true single source of truth on cloud storage, the industry turned to open table formats. Projects like Apache Iceberg and Apache Hudi (and Databricks’ Delta Lake, which later became open source) were developed to bring database-like capabilities to data lakes. In simple terms, an open table format defines how to organize data files and metadata in a data lake so that multiple compute engines can treat the data as a coherent, transactional table.
In a traditional data warehouse, you have tables that support reads and writes with ACID transactions, snapshots, schemas, etc., all managed by the warehouse DBMS. Open table formats aim to provide those same properties (ACID transactions, schema evolution, indexing) on files in a cloud object store. They maintain metadata (like table schemas, partition info, and pointers to data files) in a standard way and implement protocols for updates and concurrency control. Because the formats are open and standardized, any execution engine (Spark, Presto/Trino, Flink, Hive, etc.) that understands the table format can read and write data and still uphold consistency guarantees.
For example, Apache Iceberg introduced a table format where data files (like Parquet) are tracked by metadata files and snapshots. Each commit to an Iceberg table creates a new snapshot manifest, and engines use optimistic concurrency with atomic commits to ensure no conflicts. All engines refer to the same manifest to know which data files constitute the latest table state. This means whether you query the table via Spark or Trino or Flink, you see the same current data (and if two engines try to write, one will retry if there’s a conflict, ensuring atomicity). Iceberg was explicitly “designed to solve correctness problems in eventually-consistent cloud object stores,” offering serializable isolation so that “table changes are atomic and readers never see partial or uncommitted changes.”. In other words, it brings true ACID transactions to the data lake world, no matter which tool is reading the data.
Apache Hudi, similarly, was created (at Uber) to enable managing records on a data lake with support for upserts (update-in-place) and incremental pulls. Hudi tables can be configured for copy-on-write or merge-on-read storage, enabling streaming data ingestion and point-in-time querying. Like Iceberg, Hudi provides a layer of metadata and concurrency control on top of the raw files. It allows multiple engines (Presto, Spark, Trino, etc.) to query the same data reliably. In fact, Hudi’s documentation emphasizes this multi-engine flexibility: the goal is to “maintain a single source of truth and access the same dataset from different query engines” without duplicating data. For example, a Hudi dataset on S3 could be queried via Amazon Athena, Redshift Spectrum, Spark, or Hive, all through the same table abstraction.
These open table formats (OTFs) effectively decouple the table logic from any one processing engine. They act as an interoperability layer. A recent article by Teradata succinctly states: “OTFs enable multiple data applications to work on the same data in a transactionally consistent manner.” Instead of data fragmentation, you get data collaboration – various tools and engines, each perhaps optimized for different workloads, all operating on one storage “truth.” The table format ensures that if one tool updates a table, another tool’s query will see that update, or at least not see a half-finished update.
Another benefit is openness and avoidance of lock-in. Because formats like Iceberg and Hudi are open source standards, the data files and metadata are not tied to a single vendor’s platform. This is in contrast to, say, Snowflake’s internal storage or even BigQuery’s proprietary storage format – in those systems, if you want to use a different engine, you’re out of luck (or you have to export the data). With Iceberg or Hudi, the data lives in standard files on object storage; any engine that speaks the format can use it. This has started a virtuous cycle: the more popular these formats became, the more engines added support for them. Today, Iceberg is supported in Spark, Trino/Presto, Flink, Impala, Hive, and even commercial warehouses are adapting – Snowflake itself announced support for Iceberg tables, and BigQuery can directly query Iceberg tables via BigLake. This broad adoption validates the demand for a neutral data layer.
To illustrate how these formats ensure consistency, consider Apache Iceberg’s approach: Iceberg uses a snapshot/manifest model and a catalog (like a Hive Metastore, or a REST catalog) to record the state of the table. When an engine wants to commit a write, it creates new data files and a new manifest, then atomically updates the pointer to the latest snapshot in the catalog. If two writers collide, one will fail to update the pointer and retry (this is optimistic concurrency control). Readers always go through the catalog to find the current “pointer” to the latest snapshot, so they either see the old snapshot or the new one, never an in-between state. This internal synchronization means all tools see a consistent view of the data without needing a single monolithic query engine. The same general idea – maintain central metadata for coherence – exists in Hudi and Delta Lake as well (though implementations differ). The bottom line is that with these technologies, you can have multiple compute engines operating on a single data repository, safely and in sync.
By solving the consistency and schema management piece, open table formats essentially unlocked the lakehouse architecture. They provided the missing piece that pure storage/compute separation didn’t address: how to avoid the fragmentation and silos. Now, one could store data in one place (e.g. an “open” data lake on cloud storage) and have the functionality of a warehouse (through table formats) and the flexibility of a data lake (through multi-engine support and cheap storage). This blend is precisely what we call a data lakehouse.
The Lakehouse Paradigm: A New Model for Data Infrastructure
Armed with open table formats and the lessons of the past, the industry is now embracing the lakehouse paradigm. A data lakehouse is an architecture that combines the best elements of a data lake and a data warehouse into a unified platform. It decouples storage from compute (like the cloud warehouses do) in an open way (using formats like Iceberg/Hudi/Delta on object storage), and thus allows a wide range of compute engines to interact with the data. In effect, a lakehouse looks like a warehouse to end-users (you can run SQL and get ACID guarantees) but behaves like a lake behind the scenes (flexible storage, support for unstructured data, multiple tools, low cost).
To clarify this, it helps to explicitly list what a lakehouse inherits from each side:
- From Data Lakes: Lakehouses keep the low-cost, scalable storage of data lakes. They typically live on object stores like S3/ADLS/GCS, which means you can store all your raw data, structured or unstructured, without the size constraints of expensive warehouse storage. They also maintain the flexibility of lakes – you aren’t tied to a particular processing engine or programming model. Want to run SQL? Go ahead. Want to run a machine learning job reading the same data with Python? That works too. The storage layer is just files, so you can always access the raw data if needed. This addresses the “variety” aspect of big data – different use cases (BI, ML, streaming) can all use the same data in a lakehouse.
- From Data Warehouses: The lakehouse borrows the management and performance features that made warehouses indispensable. This includes structured tables with schemas, the ability to do ad-hoc SQL queries with good performance, indexing/pruning to speed up queries, and crucially transactional integrity (no half-written results, support for updates/deletes, etc.). In other words, the lakehouse adds a semantic layer on top of the raw files, so that using the data is as convenient as querying a warehouse. You get the reliability and query power of warehouses on your lake data.
So, a lakehouse is not just a marketing term; it’s a deliberate architecture to end the split between lakes and warehouses. In a true lakehouse, you don’t need separate copies for different workloads – it’s one storage, one table format, accessible through many tools. This greatly simplifies data engineering pipelines (no more nightly ETLs just to copy data around), and it accelerates time-to-insight, because everyone is looking at the same data repository.
“Open” at a More Fundamental Level
An important aspect of the lakehouse architecture is that it is fully open. “Open” here means using open-source formats and interfaces so that the ecosystem can thrive. In the way that Hadoop’s ecosystem benefited from HDFS being an open interface (many tools built on it), the lakehouse ecosystem benefits when storage and table format are open. We’re seeing a proliferation of query engines and specialized processing engines that can all plug into a lakehouse. For example, one company might use Apache Spark for large-scale batch jobs, Trino (Presto SQL) for interactive queries, Flink for real-time streaming, and a BI tool for dashboarding – all reading/writing the same data in-place. This was very hard to imagine in the Hadoop era or even early cloud era, where each system held its own copy. Now, thanks to table formats, it’s becoming reality.
A Cambrian Explosion of More Relevant Compute
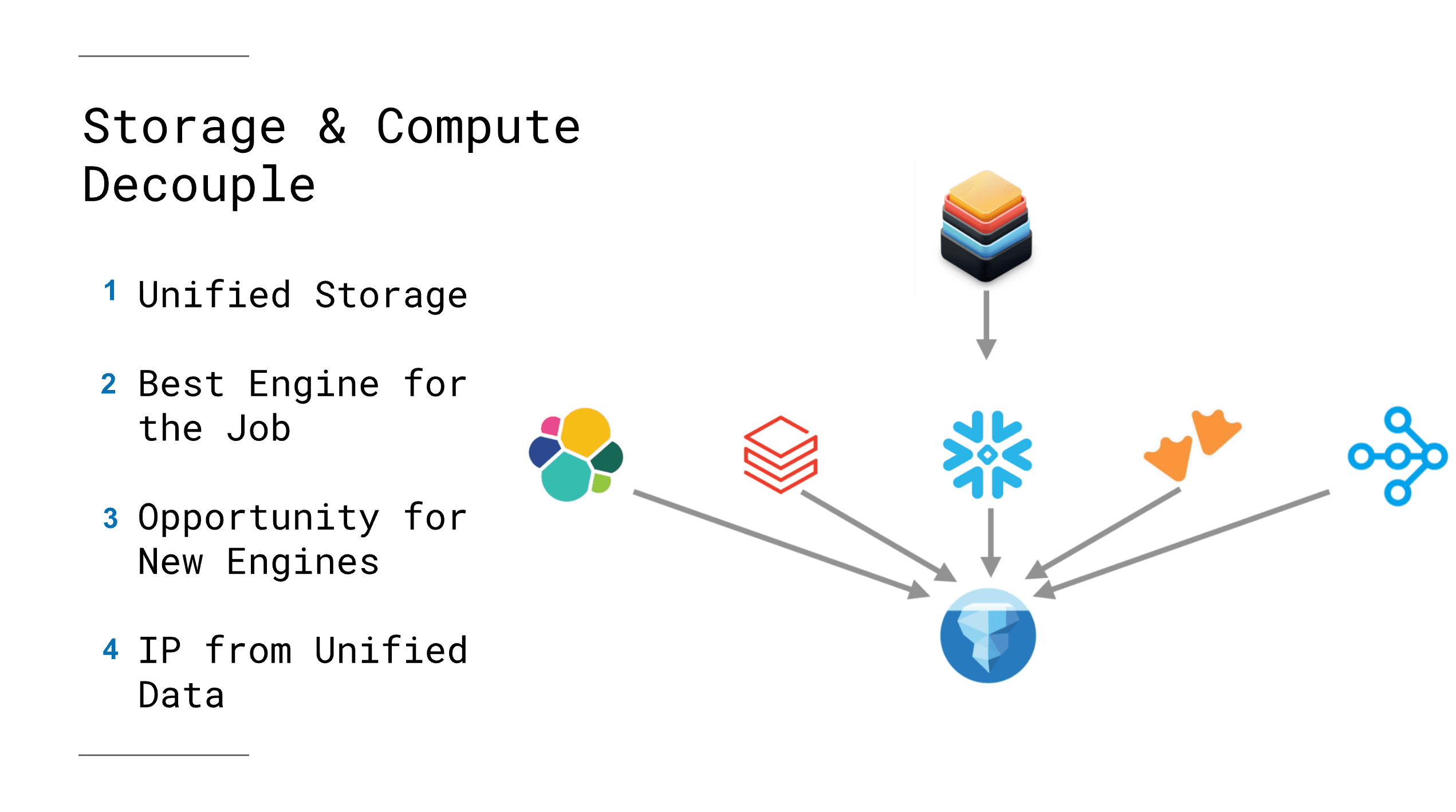
It’s useful to draw an analogy to another tech domain to appreciate this explosion of compute options. Consider the evolution of enterprise software authentication: years ago, each application had its own user logins (like each data system had its own storage). Then standards like SAML enabled Single Sign-On, and later identity providers like Okta or GSuite allowed central management of users. Suddenly, companies could adopt dozens of SaaS applications easily because they all plugged into the same identity system – users could log in everywhere with one corporate account.
This standardization of the interface (identity) led to a flourishing of many new SaaS tools, since integration was no longer a barrier. In the data world, open table formats and lakehouse architecture are analogous to that single sign-on system: they standardize the data interface (storage layer and table format), allowing a multitude of compute tools to plug in. This has led to an explosion of new data processing engines and tools, because now a niche tool can gain adoption without needing you to move your data; it just connects to the lakehouse. The playing field is leveled – established vendors and startups alike can compete on computation (query speeds, algorithms, etc.) rather than on locking you into a data silo.
We see this trend in action: for instance, Snowflake – a previously fully proprietary warehouse – is embracing openness by announcing support for Iceberg tables, effectively opening its storage layer to outside compute. This indicates that even incumbents recognize the demand for interoperability. Meanwhile, cloud vendors (Google BigQuery, AWS Athena/Glue, Azure Synapse) are all adding support for open table formats to avoid being islands. Databricks, which championed the lakehouse concept early with Delta Lake, is now also working with Iceberg and Hudi communities, indicating a broader convergence in the industry toward open lakehouse standards.
The lakehouse paradigm is becoming the new default for modern data architecture: keep data in one flexible, open repository and use whichever compute service is appropriate for the task. It promises lower total cost (no data duplication, use of cheap storage), better data integrity (one source of truth), and greater innovation (mix-and-match best-of-breed tools). It’s not without its challenges (which we address next), but it’s a logical culmination of the trends that started with Hadoop and evolved through the cloud warehouse era.
Opportunities for Innovation and the Future of the Ecosystem
The shift to lakehouse architecture is not the end of the story – it’s the opening chapter to a richer, more dynamic data ecosystem. Just as the Hadoop era spawned a vibrant ecosystem of analytics and ETL tools, and cloud data warehouses inspired their own specialized markets, the lakehouse paradigm is creating new frontiers for innovation. In an environment where inexpensive, centralized storage meets a diverse array of pluggable compute engines, several critical areas for innovation have emerged. These include performance acceleration, real-time analytics, multi-format data streaming, and verticalized, industry-specific solutions—all complemented by continued improvements in user interfaces, governance, operations, and integration.
1. Query Acceleration
While specialized data warehouses (like Snowflake and BigQuery) have evolved with highly optimized, local caching layers and vectorized execution engines, many lakehouse query engines (e.g. Trino on Iceberg) still lag behind in performance. Today, without a dedicated caching layer that leverages local disks, lakehouse queries often incur higher latencies because they must repeatedly fetch data from remote object stores. In contrast, modern warehouses cache warm data on local SSDs to deliver sub-second response times.
Innovators can develop dedicated acceleration layers for lakehouses—whether through native local-disk caching, intelligent pre-fetching, or query result reuse. By integrating a “performance tier” that mimics the fast, local cache of specialized warehouses, a lakehouse platform could deliver query speeds that rival (or even surpass) incumbent systems. Such a breakthrough would not only enhance interactive analytics on open data but also strengthen the overall value proposition of lakehouse architectures for enterprises.
2. Real-Time Analytics
The demand for real-time data has never been greater. Enterprises need fresh insights with minimal latency to support dashboards, alerting, and operational decision-making. Yet, current lakehouse frameworks often struggle with rapid ingestion and immediate queryability. For example, while solutions like Apache Hudi target near real-time ingestion, they still face limitations when it comes to sub-second query responses. In contrast, architectures such as Rockset’s ALT (Aggregator-Leaf-Tailer) are designed to index incoming events almost instantly, enabling true real-time OLAP performance.
There is significant potential for innovations that bring genuine real-time capabilities to the lakehouse ecosystem. This could involve rethinking table formats to support continuous, low-latency streaming writes and real-time indexing, or integrating tightly with message streams (e.g., Kafka or Kinesis) so that fresh data is immediately queryable. A platform that enables sub-second latency on high-frequency data would capture a vast market segment currently underserved by traditional lakehouse approaches.
3. Multi-Format Data Streaming
Today’s lakehouse implementations often expose an “impedance mismatch” between batch and streaming data workflows. In practice, enterprises frequently maintain separate pipelines and even distinct file formats for batch (e.g., Parquet via Iceberg) and streaming data (e.g., Avro via Hudi). This fragmentation not only complicates the overall architecture but also creates latency and increases engineering overhead—reminiscent of the old Lambda architecture challenges.
A unified solution that seamlessly handles both batch and streaming ingestion and consumption would be a game changer. Imagine a lakehouse platform that supports a single, coherent file format or table abstraction for both streaming updates and historical batch data—eliminating the need to convert between formats or maintain multiple pipelines. Such an innovation would simplify development and operations, reduce latency, and allow companies to treat real-time and historical data as two views of the same dataset.
4. Verticalized Lakehouses
One of the most compelling aspects of the lakehouse model is that all data resides in one central repository, making it easier to enforce consistent controls and governance. This opens a powerful opportunity for verticalized lakehouse solutions that are tailor-made for highly regulated sectors such as finance, healthcare, and government. In these industries, compliance, auditability, and robust security controls are not optional—they are mission-critical.
Startups can develop industry-specific lakehouse platforms that “bake in” regulatory and compliance features from the ground up. For example, a healthcare lakehouse might include pre-integrated data models (like FHIR), HIPAA-compliant access controls, and detailed data lineage tracking, while a financial services lakehouse could offer built-in support for SEC/FINRA compliance, risk models, and fraud detection analytics. By addressing these vertical-specific requirements, such solutions can accelerate adoption in markets where generic platforms fall short, and command premium pricing for their specialized functionality.
5. Tools and Interfaces Built for Lakehouse
Existing analytics tools need to evolve to take full advantage of the lakehouse’s open, modular architecture. Legacy BI platforms like Looker or Tableau were designed with a centralized data warehouse in mind, but a lakehouse—often built on open formats like Iceberg—enables a more modular approach. Newer BI solutions, such as Lightdash (an open source alternative that integrates with dbt), demonstrate that a stack composed of Lightdash, dbt, and engines like Trino on Iceberg can provide powerful analytics without requiring proprietary storage.
There remains significant room for innovation in creating visualization, exploration, and AI/ML tools that are native to the lakehouse environment. Startups that focus on a unified semantic layer—ensuring that business metrics remain consistent across multiple compute engines—could see high demand as enterprises seek to maximize the value of their data without duplicating storage.
6. Data Governance and Security
With the flexibility of an open lakehouse comes the challenge of ensuring robust governance, security, and compliance. Multiple compute engines accessing a single source of truth demand a centralized way to enforce data policies. Although tools like Apache Ranger, AWS Lake Formation, and Databricks Unity Catalog have emerged to address this need, gaps remain in providing truly unified metadata and access control across heterogeneous environments.
There is a clear market for innovations that offer a single pane of glass for data governance—one that spans all engines and enforces consistent policies no matter how the data is queried. Enhanced solutions might integrate automated data tagging, differential privacy controls, and lineage tracking, thereby reducing the operational burden on enterprises and bolstering trust in the platform.
7. Data Engineering Ops: Performance and Reliability
Maintaining huge tables on object storage poses its own challenges. As data is continuously appended and updated, the accumulation of small files and outdated snapshots can degrade query performance over time. Regular maintenance tasks—such as file compaction and snapshot expiration—are essential but complex, and many organizations lack the internal expertise to manage these operations at scale.
There is a strong incentive for “data ops” platforms that automate the upkeep of lakehouse data. Startups that provide managed services for file compaction, clustering, and schema evolution can help enterprises maintain fast, efficient queries. Additionally, performance optimization tools—such as cost-based query optimizers or smart caching mechanisms—offer further potential to enhance reliability and reduce operational overhead.
8. Interoperability and Integration Solutions
As the lakehouse ecosystem grows, ensuring seamless interoperability between the various compute engines, data pipelines, and monitoring tools becomes increasingly important. While many engines can read the same open table formats, in practice, integrating logs, orchestrating workflows, and providing unified observability across multiple systems remains challenging.
There is a valuable market for integration platforms that “glue” the lakehouse ecosystem together. Tools that offer unified monitoring, observability, and orchestration across diverse engines (be they Spark, Flink, or SQL-based) will help eliminate silos. Standardized interfaces—akin to an “open compute API”—and federated query layers that span multiple catalogs represent another frontier for developers aiming to simplify the multi-engine environment.
Future Outlook
In summary, while the lakehouse paradigm has solved many problems of earlier architectures, it has also introduced new challenges. The opportunities for innovation span a wide spectrum—from performance acceleration and real-time data ingestion to unified streaming pipelines and industry-specific solutions. As startups and established players address these challenges, we can expect the emergence of a rich ecosystem that not only simplifies enterprise data management but also unlocks new levels of performance, compliance, and flexibility. For venture investors and founders alike, this is a dynamic space with the potential to produce the next generation of data platform companies—ones that redefine how organizations manage, analyze, and derive value from data in a truly open and interconnected world.
Conclusion
In conclusion, the journey from Hadoop to cloud warehouses to lakehouse reflects a common theme in technology: unbundling and re-bundling. We unbundled storage and compute to get flexibility, and now lakehouse re-bundles certain functionalities at the storage layer (through open table formats) to provide unity and reliability. The result is a more open, modular, and powerful data stack. Organizations can keep a single source of truth in a cheap, scalable store, access it with any tool they need, and ensure the data remains consistent and governed. The lakehouse paradigm is still evolving, but it clearly represents the next phase of data infrastructure – one that aspires to finally deliver on the promise of “any data, anywhere, accessible and usable by any analytics.” Those building the ecosystem around it will determine how fully that promise is realized, making this a space to watch closely.

Authors
Sign up for more like this
Stay ahead of trends, get a roundup of high-quality content in your inbox every month.






