Tech-03/10/2024
Fine-tuning is all you need
Can we fine-tune an LLM on our corpus to improve the performance of our RAG pipeline? And is it possible to fine-tune a less capable LLM to match the performance of a more capable LLM?

At Moonfire, we’re using AI models in almost every part of our stack. And we’ve been doing so from the very start in 2020. Back then, before LLMs like GPT-4 were available, we did what was the industry standard: take an open source transformer model like BERT and fine-tune it on proprietary data to make it suitable for tasks that we care about. But things changed with the release of GPT-4 in 2023. We found that API-based LLMs could outperform our fine-tuned models on certain tasks, so we went through the process of replacing a lot of our own models with API calls.
This year, we’ve seen the release of a number of open source LLMs whose performance is slowly catching up to that of the API-based LLM providers like OpenAI and Anthropic. This is a really exciting development, because it allows everyone to download, fine-tune and host their own very powerful models. But everything comes at a cost. LLMs are many times larger than the models we used to work with. For context, BERT-base, a capable NLP model from the “pre-LLM” era had 110M parameters, while open source LLMs typically start at 8B parameters (e.g. the smallest Llama 3.1 model) and can get up to 405B parameters (the large Llama 3.1 model). Fine-tuning and, especially, hosting models of this size is much more complicated and costly than it was for smaller transformer models, so this might not always be an option for startups or small use cases.
Recently OpenAI released a new feature that allows you to fine-tune their flagship model GPT-4o with just an API call, or through their UI. This takes away a lot of the complexity and cost of fine-tuning LLMs. It also allows you to run experiments quickly to see if fine-tuning works for your use case or not.
With that in mind, we set out to run a few experiments ourselves. Our goal was to see if we could fine-tune an LLM to improve one of our RAG-based workflows which aims to evaluate companies with respect to how well the company aligns with our internal investment thesis.
To recap, RAG (retrieval-augmented generation) is a process where instead of just prompting an LLM with a question (that’s the generation part), you augment the prompt with additional information that you retrieve from a knowledge base (that’s the retrieval-augmented part). The knowledge base is typically a vector database that contains chunks of a large corpus of text. During the retrieval process you first get the most relevant chunks from the vector database and add these additional pieces of information to the query in order to generate a better response.
Our RAG evaluation pipeline looks like this:
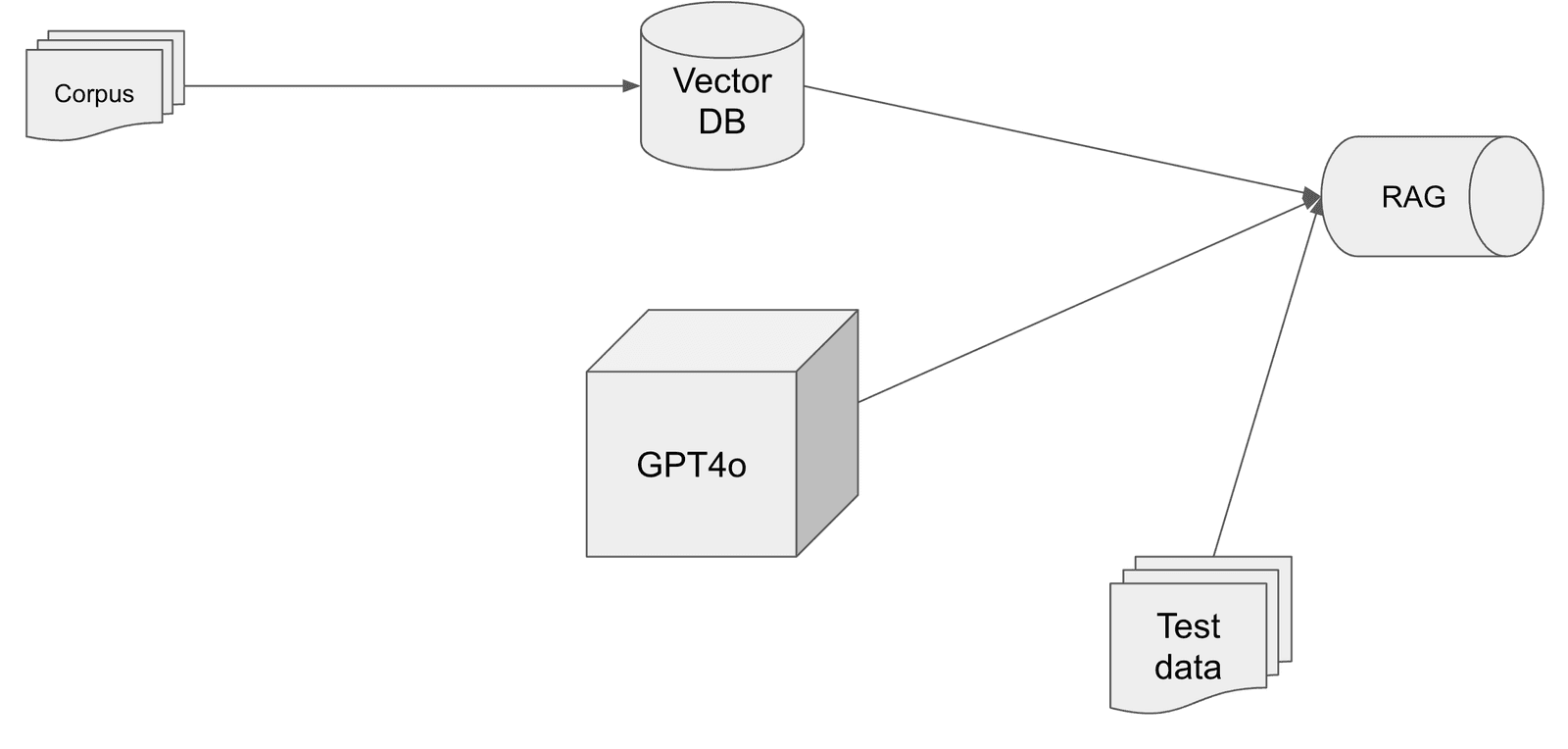
And the alternative approach looks this:
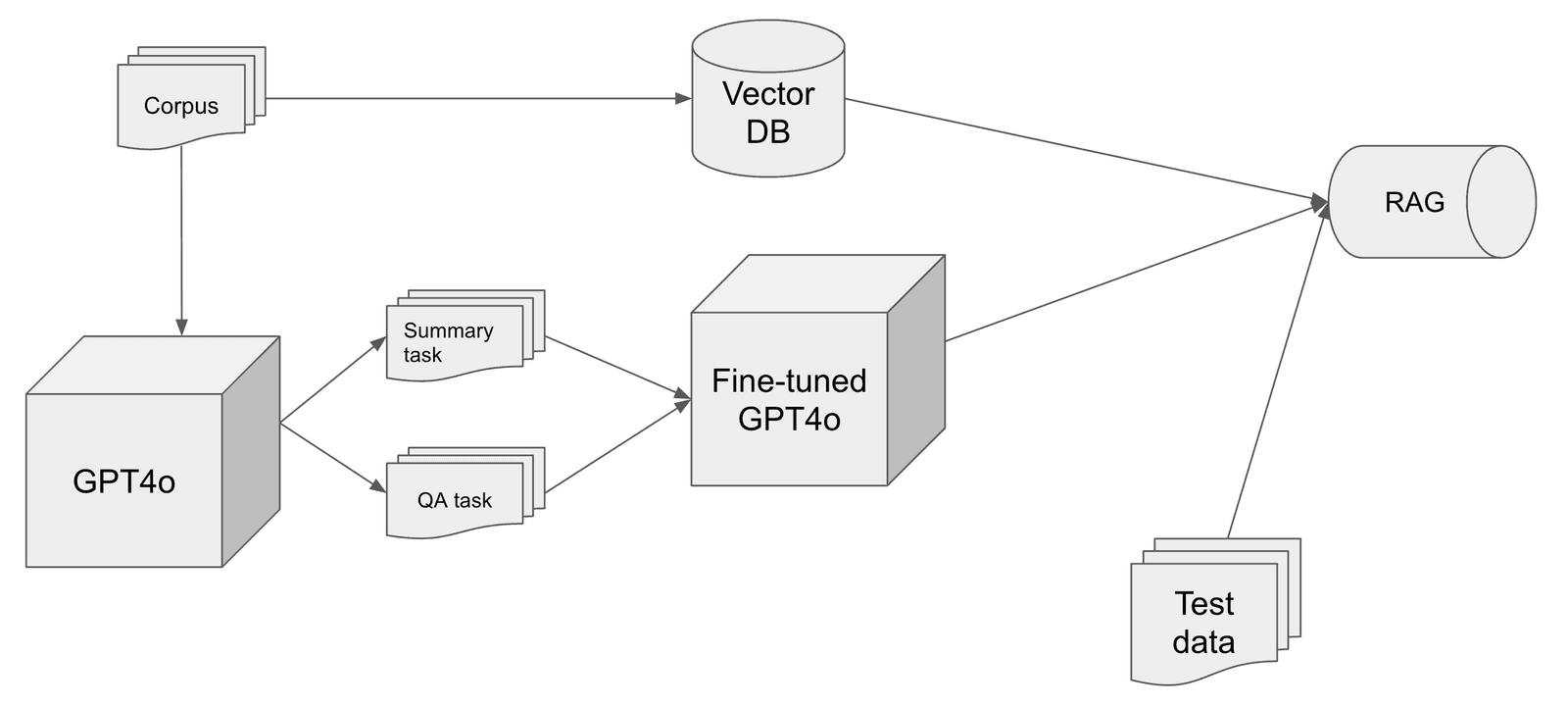
Basically we keep the RAG pipeline exactly as is (same vector DB, same hyperparameters and prompts in the RAG pipeline) and just swap out the LLM for a fine-tuned one.
The key questions we set out to answer are:
- Can we fine-tune an LLM on our corpus to improve the performance of our RAG pipeline?
- Is it possible to fine-tune a less capable LLM to match the performance of a more capable LLM?
We’re not aiming to answer these questions in general, since we only really care about our specific use case at hand. Nevertheless, these questions lead to some very interesting experiments. Instead of using snippets of our vast internal knowledge base in a vanilla RAG pipeline, can we instead ingrain this information into the model weights of the LLM? And, if so, does that lead to an increase in performance on downstream tasks? It’s not obvious that it does, so let’s find out!
The first question is how to prepare our data for fine-tuning? In this case, our data is mainly just human-written text containing relevant information, so it doesn’t really have any labels. That wouldn’t be a problem if we were fine-tuning the model on a language modelling task, but that’s not how the OpenAI fine-tuning API works (and it’s also one of the limitations in our opinion). Instead, you have to provide it with structured inputs – that is, system prompt and chat interactions between the user and agent. We found that we can generate training examples in exactly this format from our raw text using an LLM. So that’s neat and scalable; no need to create training examples by hand or label any data. The exact prompts used will vary by use case. We created two types of training tasks: a summarisation task and a QA task.
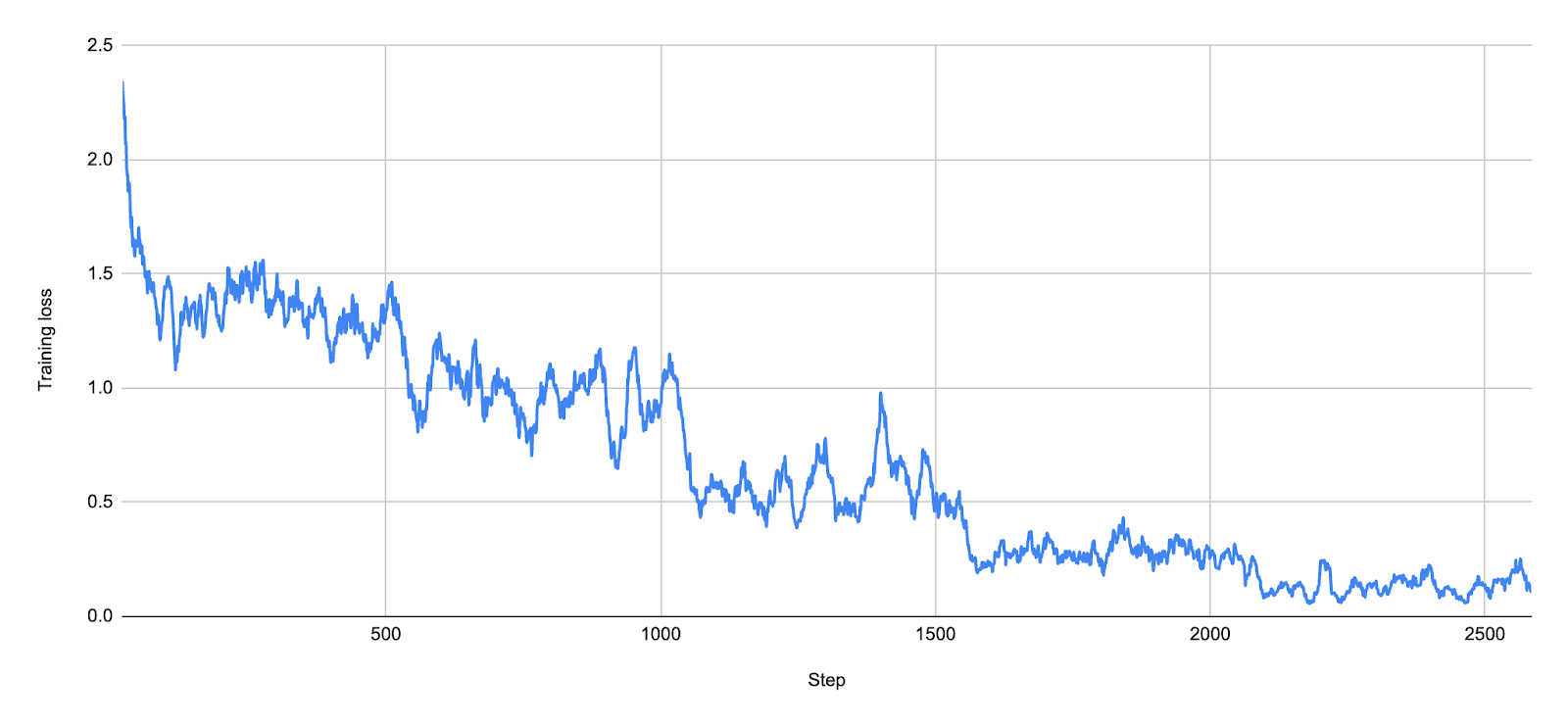
With the training data created, we can begin the fine-tuning process itself. OpenAI allows you to choose three hyperparameters: batch size (defaults to 1), learning rate multiplier (defaults to 1.8), and number of epochs (defaults to 3). Training can take anywhere from a few minutes to several hours, depending on how large your training data is and which model you’re fine-tuning (GPT-4o or GPT-4o mini). A typical training loss curve looks like the one below, where we trained for five epochs. It saves the last three checkpoints, so you can experiment a bit with which one to use.
Our task is a binary classification task (does a given company fit our investment thesis or not?), for which we have a test set so we can easily compare different models. As with any ML training, it’s important to make sure there’s no leakage of test data in our training data. In this case, we have to make sure that the generated training examples don’t explicitly mention any of the companies in the test data set!
We use two metrics to evaluate the performance:
- Average precision (AP)
- Area under the ROC curve (AUC)
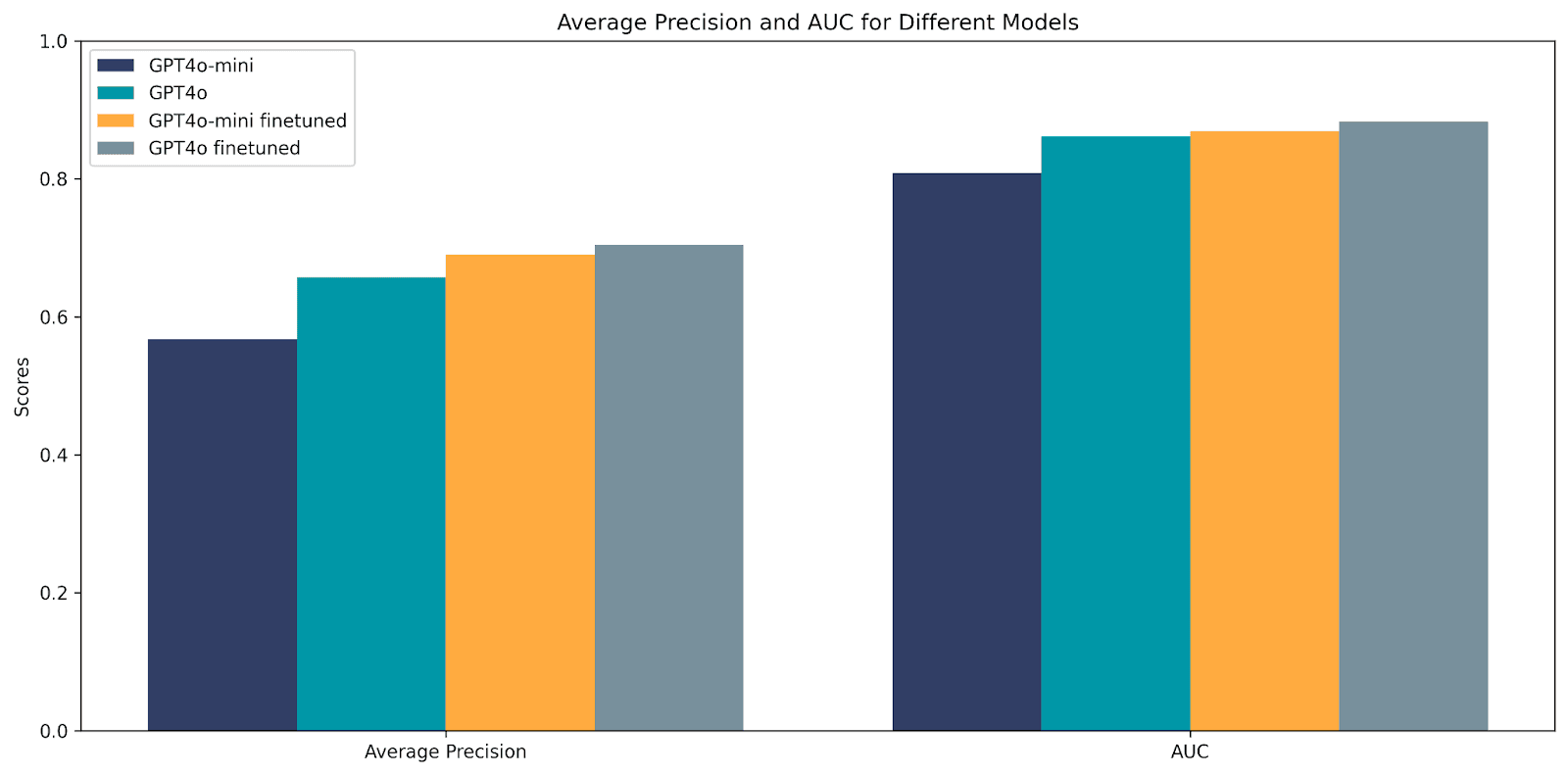
Now, to answer the questions from the beginning:
- Yes, we can increase RAG performance by fine-tuning the LLM.
- Yes, it’s possible to fine-tune a less capable LLM (GPT-4o mini) to (almost) match the performance of a more capable LLM (GPT-4o) on a RAG task.
Why does this work? A RAG pipeline only feeds a limited number of text snippets from the knowledge base to the LLM. We hypothesise that this means some useful information will be unavailable to the LLM at inference time. Using a fine-tuning approach on the other hand means that the knowledge base will be implicitly available to the LLM as part of its model weights. But fine-tuning is not the only way to improve the performance of a vanilla RAG pipeline. The alternative is to alter the hyperparameter of the RAG pipeline (e.g. number of snippets, snippet length, overlap etc) or try different RAG approaches (e.g. re-reranking).
Does this mean we should immediately adopt the fine-tuned model? We might, but, as always, the devil is in the details. While the fine-tuned model achieved a higher average precision, which summarises the precision-recall (PR) curve into a single number and is an approximation of the area under the PR curve, that doesn’t necessarily make it the best choice across all thresholds. There might be certain thresholds for which a model with a worse average precision actually achieves higher precision for a given recall – something I’ve written about before. So any preference you have for a certain minimum level of precision or recall will guide your decision on which model to use!

Sign up for more like this
Stay ahead of trends, get a roundup of high-quality content in your inbox every month.






